# LUMI Hackathon: ExaTensor
Use this collaborative document to plan your steps, discuss questions and take notes.
[Overview page of markdown syntax and HedgeDoc features like embedding pictures, pdf, links](https://md.sigma2.no/features#Table-of-Contents)
## Goals for Hackathon
1. Debug the issue of exatensor hanging on >2 nodes
2. Install exatensor/talsh as part of Dirac installation and figure out the bindings for srun in this case
3. Improve the bindings for single-node talsh library to use all available gpus and cpus
4. Profile single-node talsh and try to optimize to increase usage rate of cpus/gpus
5. Analyze internode communication of exatensor (once it works on multiple nodes)
6. Try to get our hands on working install configuration of openmpi on frontier or lumi - to help resolve issue 1.
## Source code
1. DIRAC code (https://gitlab.com/dirac/dirac) contains the ExaCorr module which we want to run on LUMI
2. It uses the CUDA based ExaTensor library (https://github.com/ORNL-QCI/ExaTENSOR)
3. The hipified branches are in our repository (https://github.com/RelMBdev/ExaTENSOR)
4. Either the the branch ```gomesasp/build-cray``` or ```remove_improbe``` are hipified
## Papers
1. Describing ExaTensor: https://onlinelibrary.wiley.com/doi/10.1002/qua.25926
2. Describing ExaCorr: https://doi.org/10.1021/acs.jctc.1c00260
## Steps and whose working on what
1. Johann: Bindings, performance tests for exatensor
2. Jan: mpi hanging issue
3. Andre: profiling+performance testing on talsh-based codes
## Notes
- speed up test on FRONTIER: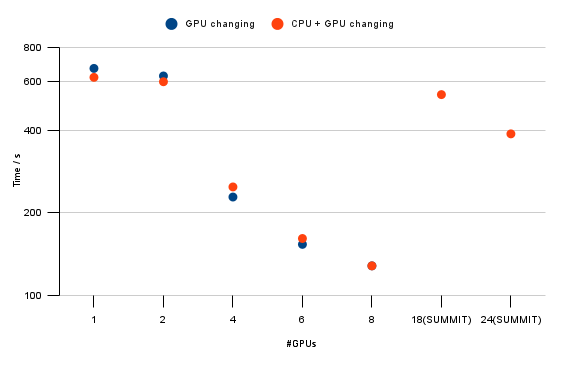
- Thierry: I have installed omnotrace and omniperf based on rocm/5.6.0 in the directory /project/project_465000828/ExaTENSOR/Thierry2578/Omni_tools. Both modules are accessible in the install directory. To see how to have access to rocm/5.0.6 module, look at the install.sh file.
I have compiled and run it, but get an error:
>rocBLAS error: Could not load /opt/rocm-5.2.3/lib/rocblas/library/TensileLibrary_gfx90a.dat
>
>rocBLAS error: Could not initialize Tensile library
>
>rocBLAS error: Could not load /opt/rocm-5.2.3/lib/rocblas/library/TensileLibrary_gfx90a.dat
>
>rocBLAS error: Could not initialize Tensile library
When I remove 'module load cray-libsci_acc' it runs further, but they I get the error:
> HSA_STATUS_ERROR_MEMORY_APERTURE_VIOLATION
## Install OpenMPI on LUMI (Alfio)
```
module load PrgEnv-gnu
module unload cray-mpich
OMPI_VERSION=4.1.6
echo "Install OpenMPI v"$OMPI_VERSION
wget https://download.open-mpi.org/release/open-mpi/v4.1/openmpi-$OMPI_VERSION.tar.bz2
tar xf openmpi-$OMPI_VERSION.tar.bz2 && rm openmpi-$OMPI_VERSION.tar.bz2
cd openmpi-$OMPI_VERSION
# SLURM (default yes), OFI, PMI
make clean
./configure --prefix=$PWD/install_ofi_slurm_pmi/ \
--with-ofi=/opt/cray/libfabric/1.15.2.0 --with-slurm --with-pmi=/usr CC=gcc CXX=g++ FTN=gfortran CFLAGS="-march=znver2" \
--disable-shared --enable-static
make -j 10 install
rm -f install
ln -s $PWD/install_ofi_slurm_pmi install
module unload cray-mpich
export PATH=$PWD/install/bin/:$PATH
export LD_LIBRARY_PATH=$PWD/install/lib:$LD_LIBRARY_PATH
# Test with OSU
wget https://mvapich.cse.ohio-state.edu/download/mvapich/osu-micro-benchmarks-5.9.tar.gz
tar xf osu-micro-benchmarks-5.9.tar.gz
rm osu-micro-benchmarks-5.9.tar.gz
cd osu-micro-benchmarks-5.9
./configure --prefix=$PWD/install CC=$(which mpicc) CXX=$(which mpicxx) CFLAGS=-O3 CXXFLAGS=-O3
make -j 10 install
cd install/libexec/osu-micro-benchmarks/mpi/p2p
srun -n 2 --ntasks-per-node=1 ./osu_bw
# Cannot remember the performance, try to compare to cray-mpich
```
## Performance data
### single contraction tests
[29/11/23 10:30]
Here are some results for a first run of a test code doing C=A*B with TAL-SH, using Omniperf.
The test was run on 1 GPU, and is such that we (a) create the tensors and copy the three of them to GPU memory; (b) each time Ompniperf runs the code, we execute the tensor contraction 10 times in a loop, and at each loop iteration we call norm2() from exacorr to do the dot product of C with itself (for checking).
[Roofline plot for FP32, test with square C8 matrices of 32768x32768 dimension](https://drive.google.com/file/d/11o5pVztOND-sy0uc0TvTnWYzQbeqmVm7/view?usp=drive_link)
[Legend for plot above](https://drive.google.com/file/d/1r6Jvs9_cA2FdS_e-7H2NHWD_U6efLp5H/view?usp=drive_link)
[Output of the test code with square C8 matrices of 32768x32768 dimension](https://drive.google.com/file/d/13SwvEWR_ssi0MhpjKwGKljDRe2WO3Su9/view?usp=drive_link)
An explanation about the plot: there are basically four types of calls in this example (a) memory copying; (b) the matrix multiply kernel; (c) the dot product; and (d) a call to fill buffer that I'm not sure now where it's being used (at initalization of TAL-SH or in initializing the actual tensor values).
The matrix multiplies, as far as I understand it, are compute bound so I guess we're good there, whereas the rest is memory bound. I will be looking now into why the dot product is the way it is, I guess/suspect it may have to do with the fact that with norm2() we're creating that on the host and need to copy back stuff.
I will continue looking at this more closely, with matrices of different size, and seeing about placing or not things in GPU memory.
[01/12/23 13:00]
In the past days modified slightly the test, specifying the device to which make the copy when calling talsh_tensor_place(). Still, it appears to be little to no difference to timings when using said function.
Have continued to gather information on performance for different problem sizes (from 1024x1024 to 16384x16384 matices) using single GPU and single OMP thread. Too much to put here, so reach me at andre.gomes at univ-lille fr for further details/data.
As it turns out Omniperf shows (as hoped/expected) that the matrix multiply kernels start to dominate execution time for 2048x2048 on up, but there's now effort to be made to understand (and hopefully improve) cache access.
Tensor block copying (gpu_tensor_block_copy_dlf__) corresponds to about 7-10% of time, and dot product (gpu_array_dot_product__) becomes negligible (1%) for larger problems.
Went back to testing TAL-SH with difference ROCM versions, and the one that appears "safest" is 5.7 (in the sense that TAL-SH tests yield the same results independent of optimization level, see [TAL-SH main repo issue #22](https://github.com/DmitryLyakh/TAL_SH/issues/22)). I will be looking into how ROCM 5.6 vs 5.7 affect the results of DIRAC (ExaCorr) tests.
In the meantime, gathering information on performance for the larger runs using more than one GPU, and OMP threads.